Design Pattern
Factory Design pattern code example in C++
1. By giving a abstract interface class or and giving object create method in concrete class derived from interface class
2. By giving object create method in Factory class
2. Factory Design pattern: defines interface to create objects. Object creation not required directly by client instead it is created in provided interface. Advantage is that client does not require to know exact class name whose object it wants to create. Also object instantiation is delayed till factory's create() method call so its like virtual constructor as exact class name is not required during compile time.
#include<iostream>
using namespace std;
#include<string.h>
class Button
{
public:
virtual void paintButton()=0;
};
class OsLinuxButton: public Button
{
public:
void paintButton()
{
cout<<"OsLinuxButton::paintButton"<<endl;
}
};
class OsWindowButton: public Button
{
public:
void paintButton()
{
cout<<"OsWindowButton::paintButton"<<endl;
}
};
class GuiFactory
{
public:
virtual Button* createButton(char* but)//No abstract
{
if(strcmp(but,"window")==0)
{
return new OsWindowButton;
}
if(strcmp(but,"linux")==0)
{
return new OsLinuxButton;
}
}
};
class Factory: public GuiFactory
{
public:
Button* createButton(char* but)
{
if(strcmp(but,"window")==0)
{
return new OsWindowButton;
}
if(strcmp(but,"linux")==0)
{
return new OsLinuxButton;
}
}
};
int main()
{
Button *button1;
GuiFactory * guifactory=new Factory;
button1 = guifactory->createButton("window");
button1->paintButton();
Button *button2;
GuiFactory * guifactory2=new Factory;
button2 = guifactory->createButton("linux");
button2->paintButton();
return 0;
}
Example 2:
//Abstract factory Design pattern: defines interface to create family of objects. Object creation not required directly by client instead it is created in provided interface. Advantage is that client does not require to know exact class name whose object it wants to create. Also objectinstantiation is delayed till factory's create() method call so its like virtual constructor as exact class name is not required during compile time.
#include<iostream>
using namespace std;
#include<string.h>
class Button
{
public:
virtual void paintButton()=0;
};
class OsLinuxButton: public Button
{
public:
void paintButton()
{
cout<<"OsLinuxButton::paintButton"<<endl;
}
};
class OsWindowButton: public Button
{
public:
void paintButton()
{
cout<<"OsWindowButton::paintButton"<<endl;
}
};
/*
class GuiFactory
{
public:
virtual Button* createButton(char* but)=0;
};
class Factory: public GuiFactory
{
public:
Button* createButton(char* but)
{
if(strcmp(but,"window")==0)
{
return new OsWindowButton;
}
if(strcmp(but,"linux")==0)
{
return new OsLinuxButton;
}
}
};
*/
int main()
{
/*
Button *button1;
GuiFactory * guifactory=new Factory;
button1 = guifactory->createButton("window");
button1->paintButton();
Button *button2;
GuiFactory * guifactory2=new Factory;
button2 = guifactory->createButton("linux");
button2->paintButton();
*/
//Without factory Object is ctreated in client code itself.
//client does new so may effect the code. Separate interface is not defined to create object.
Button *button=new OsLinuxButton;
button->paintButton();
Button *buttonWindow=new OsWindowButton;
buttonWindow->paintButton();
return 0;
}
Object pool pattern is a software creational design pattern which is used in situations where the cost of initializing a class instance is very high.
Basically, an Object pool is a container which contains some amount of objects. So, when an object is taken from the pool, it is not available in the pool until it is put back.
Objects in the pool have a lifecycle:
- Creation
- Validation
- Destroy.
UML Diagram Object Pool Design Pattern
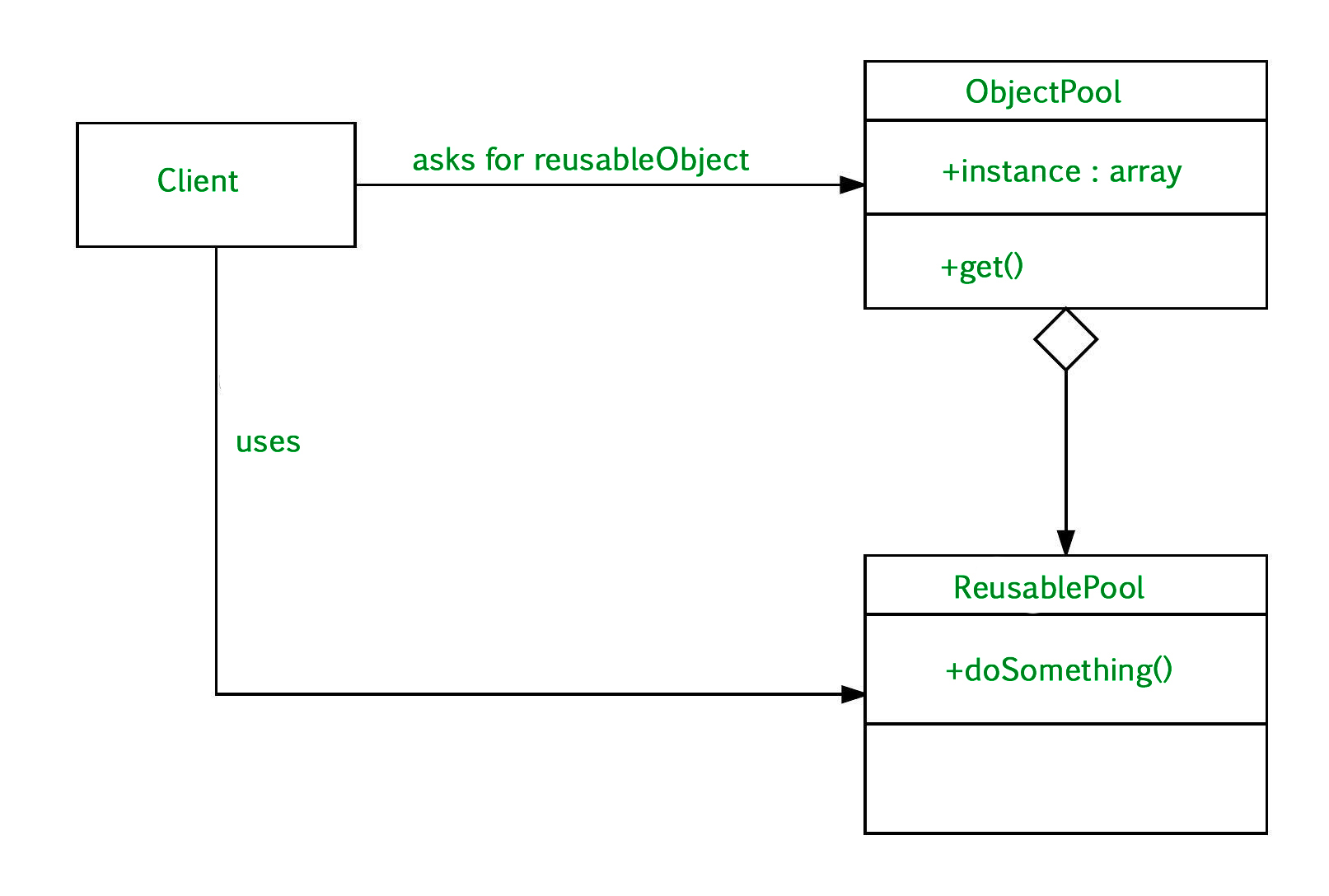
- Client : This is the class that uses an object of the PooledObject type.
- ReuseablePool: The PooledObject class is the type that is expensive or slow to instantiate, or that has limited availability, so is to be held in the object pool.
- ObjectPool : The Pool class is the most important class in the object pool design pattern. ObjectPool maintains a list of available objects and a collection of objects that have already been requested from the pool.
Let’s take the example of the database connections. It’s obviously that opening too many connections might affect the performance for several reasons:
- Creating a connection is an expensive operation.
- When there are too many connections opened it takes longer to create a new one and the database server will become overloaded.
Here the object pool manages the connections and provide a way to reuse and share them. It can also limit the maximum number of objects that can be created.
| #include <string> | |
| #include <iostream> | |
| #include <list> | |
| class Resource | |
| { | |
| int value; | |
| public: | |
| Resource() | |
| { | |
| value = 0; | |
| } | |
| void reset() | |
| { | |
| value = 0; | |
| } | |
| int getValue() | |
| { | |
| return value; | |
| } | |
| void setValue(int number) | |
| { | |
| value = number; | |
| } | |
| }; | |
| /* Note, that this class is a singleton. */ | |
| class ObjectPool | |
| { | |
| private: | |
| std::list<Resource*> resources; | |
| static ObjectPool* instance; | |
| ObjectPool() {} | |
| public: | |
| /** | |
| * Static method for accessing class instance. | |
| * Part of Singleton design pattern. | |
| * | |
| * @return ObjectPool instance. | |
| */ | |
| static ObjectPool* getInstance() | |
| { | |
| if (instance == 0) | |
| { | |
| instance = new ObjectPool; | |
| } | |
| return instance; | |
| } | |
| /** | |
| * Returns instance of Resource. | |
| * | |
| * New resource will be created if all the resources | |
| * were used at the time of the request. | |
| * | |
| * @return Resource instance. | |
| */ | |
| Resource* getResource() | |
| { | |
| if (resources.empty()) | |
| { | |
| std::cout << "Creating new." << std::endl; | |
| return new Resource; | |
| } | |
| else | |
| { | |
| std::cout << "Reusing existing." << std::endl; | |
| Resource* resource = resources.front(); | |
| resources.pop_front(); | |
| return resource; | |
| } | |
| } | |
| /** | |
| * Return resource back to the pool. | |
| * | |
| * The resource must be initialized back to | |
| * the default settings before someone else | |
| * attempts to use it. | |
| * | |
| * @param object Resource instance. | |
| * @return void | |
| */ | |
| void returnResource(Resource* object) | |
| { | |
| object->reset(); | |
| resources.push_back(object); | |
| } | |
| }; | |
| ObjectPool* ObjectPool::instance = 0; | |
| int main() | |
| { | |
| ObjectPool* pool = ObjectPool::getInstance(); | |
| Resource* one; | |
| Resource* two; | |
| /* Resources will be created. */ | |
| one = pool->getResource(); | |
| one->setValue(10); | |
| std::cout << "one = " << one->getValue() << " [" << one << "]" << std::endl; | |
| two = pool->getResource(); | |
| two->setValue(20); | |
| std::cout << "two = " << two->getValue() << " [" << two << "]" << std::endl; | |
| pool->returnResource(one); | |
| pool->returnResource(two); | |
| /* Resources will be reused. | |
| * Notice that the value of both resources were reset back to zero. | |
| */ | |
| one = pool->getResource(); | |
| std::cout << "one = " << one->getValue() << " [" << one << "]" << std::endl; | |
| two = pool->getResource(); | |
| std::cout << "two = " << two->getValue() << " [" << two << "]" << std::endl; | |
| return 0; | |
| } |
Advantages
- It offers a significant performance boost.
- It manages the connections and provides a way to reuse and share them.
- Object pool pattern is used when the rate of initializing an instance of the class is high.
When to use Object Pool Design Pattern
- When we have a work to allocates or deallocates many objects
- Also, when we know that we have a limited number of objects that will be in memory at the same time.
Strategy in C++
Strategy is a behavioral design pattern that turns a set of behaviors into objects and makes them interchangeable inside original context object.
The original object, called context, holds a reference to a strategy object and delegates it executing the behavior. In order to change the way the context performs its work, other objects may replace the currently linked strategy object with another one.
Usage of the pattern in C++
Usage examples: The Strategy pattern is very common in C++ code. It’s often used in various frameworks to provide users a way to change the behavior of a class without extending it.
Identification: Strategy pattern can be recognized by a method that lets nested object do the actual work, as well as the setter that allows replacing that object with a different one.
Conceptual Example
This example illustrates the structure of the Strategy design pattern. It focuses on answering these questions:
- What classes does it consist of?
- What roles do these classes play?
- In what way the elements of the pattern are related?
/**
* The Strategy interface declares operations common to all supported versions
* of some algorithm.
*
* The Context uses this interface to call the algorithm defined by Concrete
* Strategies.
*/
class Strategy
{
public:
virtual ~Strategy() {}
virtual std::string DoAlgorithm(const std::vector<std::string> &data) const = 0;
};
/**
* The Context defines the interface of interest to clients.
*/
class Context
{
/**
* @var Strategy The Context maintains a reference to one of the Strategy
* objects. The Context does not know the concrete class of a strategy. It
* should work with all strategies via the Strategy interface.
*/
private:
Strategy *strategy_;
/**
* Usually, the Context accepts a strategy through the constructor, but also
* provides a setter to change it at runtime.
*/
public:
Context(Strategy *strategy = nullptr) : strategy_(strategy)
{
}
~Context()
{
delete this->strategy_;
}
/**
* Usually, the Context allows replacing a Strategy object at runtime.
*/
void set_strategy(Strategy *strategy)
{
delete this->strategy_;
this->strategy_ = strategy;
}
/**
* The Context delegates some work to the Strategy object instead of
* implementing +multiple versions of the algorithm on its own.
*/
void DoSomeBusinessLogic() const
{
// ...
std::cout << "Context: Sorting data using the strategy (not sure how it'll do it)\n";
std::string result = this->strategy_->DoAlgorithm(std::vector<std::string>{"a", "e", "c", "b", "d"});
std::cout << result << "\n";
// ...
}
};
/**
* Concrete Strategies implement the algorithm while following the base Strategy
* interface. The interface makes them interchangeable in the Context.
*/
class ConcreteStrategyA : public Strategy
{
public:
std::string DoAlgorithm(const std::vector<std::string> &data) const override
{
std::string result;
std::for_each(std::begin(data), std::end(data), [&result](const std::string &letter) {
result += letter;
});
std::sort(std::begin(result), std::end(result));
return result;
}
};
class ConcreteStrategyB : public Strategy
{
std::string DoAlgorithm(const std::vector<std::string> &data) const override
{
std::string result;
std::for_each(std::begin(data), std::end(data), [&result](const std::string &letter) {
result += letter;
});
std::sort(std::begin(result), std::end(result));
for (int i = 0; i < result.size() / 2; i++)
{
std::swap(result[i], result[result.size() - i - 1]);
}
return result;
}
};
/**
* The client code picks a concrete strategy and passes it to the context. The
* client should be aware of the differences between strategies in order to make
* the right choice.
*/
void ClientCode()
{
Context *context = new Context(new ConcreteStrategyA);
std::cout << "Client: Strategy is set to normal sorting.\n";
context->DoSomeBusinessLogic();
std::cout << "\n";
std::cout << "Client: Strategy is set to reverse sorting.\n";
context->set_strategy(new ConcreteStrategyB);
context->DoSomeBusinessLogic();
delete context;
}
int main()
{
ClientCode();
return 0;
}
Output.txt: Execution result
Client: Strategy is set to normal sorting.
Context: Sorting data using the strategy (not sure how it'll do it)
abcde
Client: Strategy is set to reverse sorting.
Context: Sorting data using the strategy (not sure how it'll do it)
edcba
Strategy
Intent
Strategy is a behavioral design pattern that lets you define a family of algorithms, put each of them into a separate class, and make their objects interchangeable.

Problem
One day you decided to create a navigation app for casual travelers. The app was centered around a beautiful map which helped users quickly orient themselves in any city.
One of the most requested features for the app was automatic route planning. A user should be able to enter an address and see the fastest route to that destination displayed on the map.
The first version of the app could only build the routes over roads. People who traveled by car were bursting with joy. But apparently, not everybody likes to drive on their vacation. So with the next update, you added an option to build walking routes. Right after that, you added another option to let people use public transport in their routes.
However, that was only the beginning. Later you planned to add route building for cyclists. And even later, another option for building routes through all of a city’s tourist attractions.
The code of the navigator became bloated.
While from a business perspective the app was a success, the technical part caused you many headaches. Each time you added a new routing algorithm, the main class of the navigator doubled in size. At some point, the beast became too hard to maintain.
Any change to one of the algorithms, whether it was a simple bug fix or a slight adjustment of the street score, affected the whole class, increasing the chance of creating an error in already-working code.
In addition, teamwork became inefficient. Your teammates, who had been hired right after the successful release, complain that they spend too much time resolving merge conflicts. Implementing a new feature requires you to change the same huge class, conflicting with the code produced by other people.
Solution
The Strategy pattern suggests that you take a class that does something specific in a lot of different ways and extract all of these algorithms into separate classes called strategies.
The original class, called context, must have a field for storing a reference to one of the strategies. The context delegates the work to a linked strategy object instead of executing it on its own.
The context isn’t responsible for selecting an appropriate algorithm for the job. Instead, the client passes the desired strategy to the context. In fact, the context doesn’t know much about strategies. It works with all strategies through the same generic interface, which only exposes a single method for triggering the algorithm encapsulated within the selected strategy.
This way the context becomes independent of concrete strategies, so you can add new algorithms or modify existing ones without changing the code of the context or other strategies.
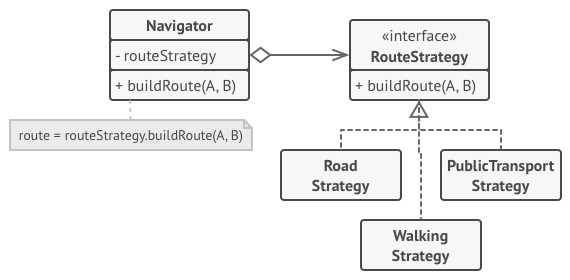
How to Implement
In the context class, identify an algorithm that’s prone to frequent changes. It may also be a massive conditional that selects and executes a variant of the same algorithm at runtime.
Declare the strategy interface common to all variants of the algorithm.
One by one, extract all algorithms into their own classes. They should all implement the strategy interface.
In the context class, add a field for storing a reference to a strategy object. Provide a setter for replacing values of that field. The context should work with the strategy object only via the strategy interface. The context may define an interface which lets the strategy access its data.
Clients of the context must associate it with a suitable strategy that matches the way they expect the context to perform its primary job.
Pros and Cons
- You can swap algorithms used inside an object at runtime.
- You can isolate the implementation details of an algorithm from the code that uses it.
- You can replace inheritance with composition.
- Open/Closed Principle. You can introduce new strategies without having to change the context.
- If you only have a couple of algorithms and they rarely change, there’s no real reason to overcomplicate the program with new classes and interfaces that come along with the pattern.
- Clients must be aware of the differences between strategies to be able to select a proper one.
- A lot of modern programming languages have functional type support that lets you implement different versions of an algorithm inside a set of anonymous functions. Then you could use these functions exactly as you’d have used the strategy objects, but without bloating your code with extra classes and interfaces.
Relations with Other Patterns
Bridge, State, Strategy (and to some degree Adapter) have very similar structures. Indeed, all of these patterns are based on composition, which is delegating work to other objects. However, they all solve different problems. A pattern isn’t just a recipe for structuring your code in a specific way. It can also communicate to other developers the problem the pattern solves.
Command and Strategy may look similar because you can use both to parameterize an object with some action. However, they have very different intents.
You can use Command to convert any operation into an object. The operation’s parameters become fields of that object. The conversion lets you defer execution of the operation, queue it, store the history of commands, send commands to remote services, etc.
On the other hand, Strategy usually describes different ways of doing the same thing, letting you swap these algorithms within a single context class.
Decorator lets you change the skin of an object, while Strategy lets you change the guts.
Template Method is based on inheritance: it lets you alter parts of an algorithm by extending those parts in subclasses. Strategy is based on composition: you can alter parts of the object’s behavior by supplying it with different strategies that correspond to that behavior. Template Method works at the class level, so it’s static. Strategy works on the object level, letting you switch behaviors at runtime.
State can be considered as an extension of Strategy. Both patterns are based on composition: they change the behavior of the context by delegating some work to helper objects. Strategy makes these objects completely independent and unaware of each other. However, State doesn’t restrict dependencies between concrete states, letting them alter the state of the context at will.
Template Method
Intent
Template Method is a behavioral design pattern that defines the skeleton of an algorithm in the superclass but lets subclasses override specific steps of the algorithm without changing its structure.

Problem
Imagine that you’re creating a data mining application that analyzes corporate documents. Users feed the app documents in various formats (PDF, DOC, CSV), and it tries to extract meaningful data from these docs in a uniform format.
The first version of the app could work only with DOC files. In the following version, it was able to support CSV files. A month later, you “taught” it to extract data from PDF files.
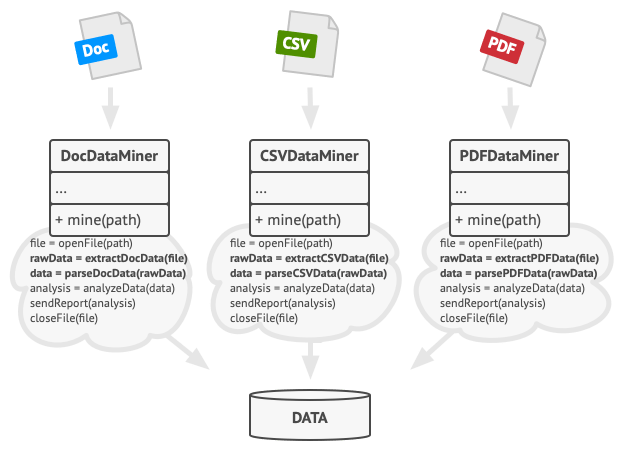
Data mining classes contained a lot of duplicate code.
At some point, you noticed that all three classes have a lot of similar code. While the code for dealing with various data formats was entirely different in all classes, the code for data processing and analysis is almost identical. Wouldn’t it be great to get rid of the code duplication, leaving the algorithm structure intact?
There was another problem related to client code that used these classes. It had lots of conditionals that picked a proper course of action depending on the class of the processing object. If all three processing classes had a common interface or a base class, you’d be able to eliminate the conditionals in client code and use polymorphism when calling methods on a processing object.
Solution
The Template Method pattern suggests that you break down an algorithm into a series of steps, turn these steps into methods, and put a series of calls to these methods inside a single template method. The steps may either be abstract, or have some default implementation. To use the algorithm, the client is supposed to provide its own subclass, implement all abstract steps, and override some of the optional ones if needed (but not the template method itself).
Let’s see how this will play out in our data mining app. We can create a base class for all three parsing algorithms. This class defines a template method consisting of a series of calls to various document-processing steps.
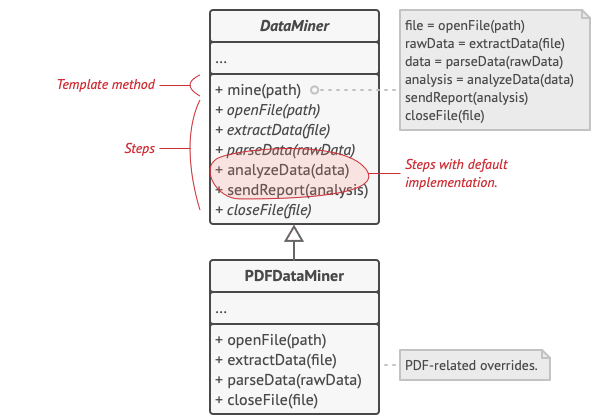
Template method breaks the algorithm into steps, allowing subclasses to override these steps but not the actual method.
At first, we can declare all steps abstract, forcing the subclasses to provide their own implementations for these methods. In our case, subclasses already have all necessary implementations, so the only thing we might need to do is adjust signatures of the methods to match the methods of the superclass.
Now, let’s see what we can do to get rid of the duplicate code. It looks like the code for opening/closing files and extracting/parsing data is different for various data formats, so there’s no point in touching those methods. However, implementation of other steps, such as analyzing the raw data and composing reports, is very similar, so it can be pulled up into the base class, where subclasses can share that code.
As you can see, we’ve got two types of steps:
- abstract steps must be implemented by every subclass
- optional steps already have some default implementation, but still can be overridden if needed
There’s another type of step, called hooks. A hook is an optional step with an empty body. A template method would work even if a hook isn’t overridden. Usually, hooks are placed before and after crucial steps of algorithms, providing subclasses with additional extension points for an algorithm.
Real-World Analogy
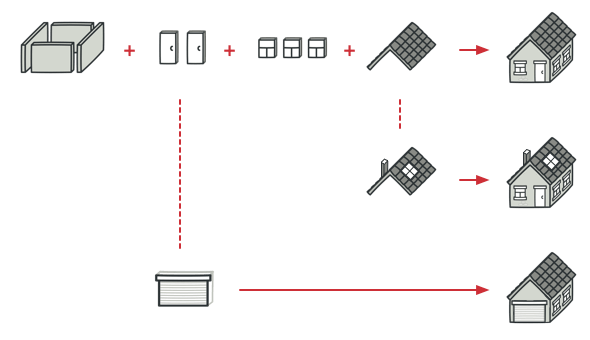
A typical architectural plan can be slightly altered to better fit the client’s needs.
The template method approach can be used in mass housing construction. The architectural plan for building a standard house may contain several extension points that would let a potential owner adjust some details of the resulting house.
Each building step, such as laying the foundation, framing, building walls, installing plumbing and wiring for water and electricity, etc., can be slightly changed to make the resulting house a little bit different from others.
Structure

The Abstract Class declares methods that act as steps of an algorithm, as well as the actual template method which calls these methods in a specific order. The steps may either be declared
abstractor have some default implementation.Concrete Classes can override all of the steps, but not the template method itself.
Pseudocode
In this example, the Template Method pattern provides a “skeleton” for various branches of artificial intelligence in a simple strategy video game.
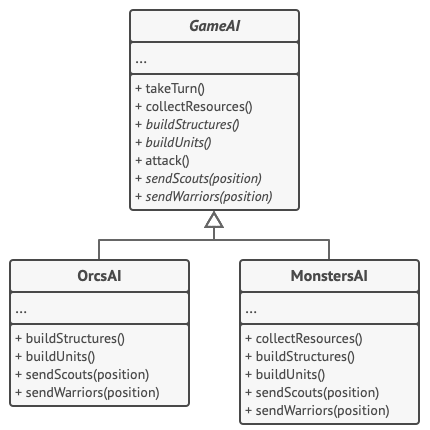
AI classes of a simple video game.
Applicability
Use the Template Method pattern when you want to let clients extend only particular steps of an algorithm, but not the whole algorithm or its structure.
The Template Method lets you turn a monolithic algorithm into a series of individual steps which can be easily extended by subclasses while keeping intact the structure defined in a superclass.
Use the pattern when you have several classes that contain almost identical algorithms with some minor differences. As a result, you might need to modify all classes when the algorithm changes.
When you turn such an algorithm into a template method, you can also pull up the steps with similar implementations into a superclass, eliminating code duplication. Code that varies between subclasses can remain in subclasses.
How to Implement
Analyze the target algorithm to see whether you can break it into steps. Consider which steps are common to all subclasses and which ones will always be unique.
Create the abstract base class and declare the template method and a set of abstract methods representing the algorithm’s steps. Outline the algorithm’s structure in the template method by executing corresponding steps. Consider making the template method
finalto prevent subclasses from overriding it.It’s okay if all the steps end up being abstract. However, some steps might benefit from having a default implementation. Subclasses don’t have to implement those methods.
Think of adding hooks between the crucial steps of the algorithm.
For each variation of the algorithm, create a new concrete subclass. It must implement all of the abstract steps, but may also override some of the optional ones.
Pros and Cons
- You can let clients override only certain parts of a large algorithm, making them less affected by changes that happen to other parts of the algorithm.
- You can pull the duplicate code into a superclass.
- Some clients may be limited by the provided skeleton of an algorithm.
- You might violate the Liskov Substitution Principle by suppressing a default step implementation via a subclass.
- Template methods tend to be harder to maintain the more steps they have.
Relations with Other Patterns
Factory Method is a specialization of Template Method. At the same time, a Factory Method may serve as a step in a large Template Method.
Template Method is based on inheritance: it lets you alter parts of an algorithm by extending those parts in subclasses. Strategy is based on composition: you can alter parts of the object’s behavior by supplying it with different strategies that correspond to that behavior. Template Method works at the class level, so it’s static. Strategy works on the object level, letting you switch behaviors at runtime.
Template Method is a behavioral design pattern that allows you to defines a skeleton of an algorithm in a base class and let subclasses override the steps without changing the overall algorithm’s structure.
/**
* The Abstract Class defines a template method that contains a skeleton of some
* algorithm, composed of calls to (usually) abstract primitive operations.
*
* Concrete subclasses should implement these operations, but leave the template
* method itself intact.
*/
class AbstractClass {
/**
* The template method defines the skeleton of an algorithm.
*/
public:
void TemplateMethod() const {
this->BaseOperation1();
this->RequiredOperations1();
this->BaseOperation2();
this->Hook1();
this->RequiredOperation2();
this->BaseOperation3();
this->Hook2();
}
/**
* These operations already have implementations.
*/
protected:
void BaseOperation1() const {
std::cout << "AbstractClass says: I am doing the bulk of the work\n";
}
void BaseOperation2() const {
std::cout << "AbstractClass says: But I let subclasses override some operations\n";
}
void BaseOperation3() const {
std::cout << "AbstractClass says: But I am doing the bulk of the work anyway\n";
}
/**
* These operations have to be implemented in subclasses.
*/
virtual void RequiredOperations1() const = 0;
virtual void RequiredOperation2() const = 0;
/**
* These are "hooks." Subclasses may override them, but it's not mandatory
* since the hooks already have default (but empty) implementation. Hooks
* provide additional extension points in some crucial places of the
* algorithm.
*/
virtual void Hook1() const {}
virtual void Hook2() const {}
};
/**
* Concrete classes have to implement all abstract operations of the base class.
* They can also override some operations with a default implementation.
*/
class ConcreteClass1 : public AbstractClass {
protected:
void RequiredOperations1() const override {
std::cout << "ConcreteClass1 says: Implemented Operation1\n";
}
void RequiredOperation2() const override {
std::cout << "ConcreteClass1 says: Implemented Operation2\n";
}
};
/**
* Usually, concrete classes override only a fraction of base class' operations.
*/
class ConcreteClass2 : public AbstractClass {
protected:
void RequiredOperations1() const override {
std::cout << "ConcreteClass2 says: Implemented Operation1\n";
}
void RequiredOperation2() const override {
std::cout << "ConcreteClass2 says: Implemented Operation2\n";
}
void Hook1() const override {
std::cout << "ConcreteClass2 says: Overridden Hook1\n";
}
};
/**
* The client code calls the template method to execute the algorithm. Client
* code does not have to know the concrete class of an object it works with, as
* long as it works with objects through the interface of their base class.
*/
void ClientCode(AbstractClass *class_) {
// ...
class_->TemplateMethod();
// ...
}
int main() {
std::cout << "Same client code can work with different subclasses:\n";
ConcreteClass1 *concreteClass1 = new ConcreteClass1;
ClientCode(concreteClass1);
std::cout << "\n";
std::cout << "Same client code can work with different subclasses:\n";
ConcreteClass2 *concreteClass2 = new ConcreteClass2;
ClientCode(concreteClass2);
delete concreteClass1;
delete concreteClass2;
return 0;
}
Output.txt: Execution result
Same client code can work with different subclasses:
AbstractClass says: I am doing the bulk of the work
ConcreteClass1 says: Implemented Operation1
AbstractClass says: But I let subclasses override some operations
ConcreteClass1 says: Implemented Operation2
AbstractClass says: But I am doing the bulk of the work anyway
Same client code can work with different subclasses:
AbstractClass says: I am doing the bulk of the work
ConcreteClass2 says: Implemented Operation1
AbstractClass says: But I let subclasses override some operations
ConcreteClass2 says: Overridden Hook1
ConcreteClass2 says: Implemented Operation2
AbstractClass says: But I am doing the bulk of the work anyway
Comments
Post a Comment